Datasets
This is a list of datasets that use Freesound content, sorted alphabetically. Do yo have a dataset that uses Freesound and does not appear here? Please send us an email at freesound@freesound.org!
-
ARCA23K
ARCA23K is a dataset of labelled sound events created to investigate real-world label noise. It contains 23,727 audio clips originating from Freesound, and each clip belongs to one of 70 classes taken from the AudioSet ontology. The dataset was created using an entirely automated process with no manual verification of the data. For this reason, many clips are expected to be labelled incorrectly.
In addition to ARCA23K, this release includes a companion dataset called ARCA23K-FSD, which is a single-label subset of the FSD50K dataset. ARCA23K-FSD contains the same sound classes as ARCA23K and the same number of audio clips per class. As it is a subset of FSD50K, each clip and its label have been manually verified. Note that only the ground truth data of ARCA23K-FSD is distributed in this release. To download the audio clips, please visit the Zenodo page for FSD50K.
The source code used to create the datasets is available: https://github.com/tqbl/arca23k-dataset
Turab Iqbal, Tin Cao, Andrew Bailey, Mark D. Plumbley, Wenwu Wang
University of Surrey, Centre for Vision, Speech and Signal Processing, Audio Research Group
-
BSD10k
The BSD10k dataset (Broad Sound Dataset 10k) is an open collection of human-labeled sounds containing over 10,000 Freesound audio clips, annotated according to the 23 second-level classes defined in the Broad Sound Taxonomy (BST). BST is currently being used in Freesound for organization, filtering, and post-processing tasks. The dataset was created at the Music Technology Group of Universitat Pompeu Fabra. For more information about the dataset, download instructions, and citation details, please check the Zenodo BSD10k page.
Panagiota Anastasopoulou, Jessica Torrey, Frederic Font, Xavier Serra
Music Technology Group (MTG), Universitat Pompeu Fabra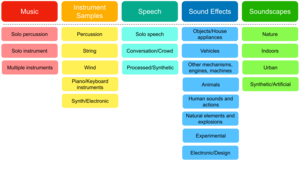
-
Clotho Dataset
Clotho is a novel audio captioning dataset, consisting of 4981 audio samples, and each audio sample has five captions (a total of 24 905 captions). Audio samples are of 15 to 30 s duration and captions are eight to 20 words long. Audio samples are collected from Freesound.
Konstantinos Drossos, Samuel Lipping, Tuomas Virtanen
Tampere University -
Dataset used in COALA: Co-Aligned Autoencoders for Learning Semantically Enriched Audio Representations
This dataset consists of two hdf5 files that contain pre-computed log-mel spectrograms that have been used to to train audio embedding models. The dataset is split into a training set and a validation set containing respectively 170793 and 19103 spectrogram patches with their accompanying multi-hot encoded tags from a vocabulary of 1000 tags provided by Freesound users.
More details can be found in “COALA: Co-Aligned Autoencoders for Learning Semantically Enriched Audio Representations” by X. Favory, K. Drossos, T. Virtanen, and X. Serra. (arXiv)
Xavier Favory, Konstantinos Drossos, Tuomas Virtanen, Xavier Serra
Music Technology Group (MTG), Universitat Pompeu Fabra -
DBR Dataset
DBR dataset is an environmental audio dataset created for the Bachelor’s Seminar in Signal Processing in Tampere University of Technology. The samples in the dataset were collected from the online audio database Freesound. The dataset consists of three classes, each containing 50 samples, and the classes are ‘dog’, ‘bird’, and ‘rain’ (hence the name DBR).
Ville-Veikko Eklund
Tampere University -
DCASE2019 Task 4 - Sythetic data
The synthetic set is composed of 10 sec audio clips generated with Scaper. The foreground events are obtained from a subset of FSD dataset from Freesound. Each event audio clip was verified manually to ensure that the sound quality and the event-to-background ratio were sufficient to be used an isolated event. We also verified that the event was actually dominant in the clip and we controlled if the event onset and offset are present in the clip.
Turpault Nicolas, Serizel Romain, Salamon Justin, Shah Ankit Parag
Université de Lorraine, CNRS, Inria, Language Technologies Institute, Carnegie Mellon University, Adobe Research -
DESED Synthetic
This dataset is the synthetic part of the DESED dataset. It allows creating new mixtures from isolated foreground sounds and background sounds, and was used in DCASE 2019 and DCASE2020 task 4 challenges.
Turpault, Nicolas, Serizel, Romain, Salamon, Justin, Shah, Ankit, Wisdom, Scott, Hershey, John, Erdogan, Hakan
Université de Lorraine, CNRS, Inria, Language Technologies Institute, Carnegie Mellon University, Adobe Research, Google, Inc -
Divide and Remaster (DnR)
Divide and Remaster (DnR) is a source separation dataset for training and testing algorithms that separate a monaural audio signal into speech, music, and sound effects/background stems. The dataset is composed of artificial mixtures using audio from the librispeech, free music archive (FMA), and Freesound Dataset 50k (FSD50k). We introduce it as part of the Cocktail Fork Problem paper: https://arxiv.org/abs/2110.09958
Darius Petermann, Gordon Wichern, Zhong-Qiu Wang, Jonathan Le Roux
Mitsubishi Electric Research Laboratories (MERL), Cambridge, MA, USA, Indiana University, Department of Intelligent Systems Engineering, Bloomington, IN, USA -
Emo-Soundscapes
We propose a dataset of audio samples called Emo-Soundscapes and two evaluation protocols for machine learning models. We curated 600 soundscape recordings in Freesound.org and mixed 613 audio clips from a combination of these. The Emo- Soundscapes dataset contains 1213 6-second Creative Commons licensed audio clips. We collected the ground truth annotations of perceived emotion in 1213 soundscape recordings using a crowdsourcing listening experiment, where 1182 annotators from 74 different countries rank the audio clips according to the perceived valence/arousal. This dataset allows studying soundscape emotion recognition and how the mixing of various soundscape recordings influences their perceived emotion.
Jianyu Fan, Miles Thorogood, Philippe Pasquier
Simon Fraser University -
ESC-50: Dataset for Environmental Sound Classification
The ESC-50 dataset is a labeled collection of 2000 environmental audio recordings suitable for benchmarking methods of environmental sound classification. The dataset consists of 5-second-long recordings organized into 50 semantical classes (with 40 examples per class) loosely arranged into 5 major categories. Clips in this dataset have been manually extracted from public field recordings gathered from Freesound.
Piczak, Karol J.
Warsaw University of Technology -
freefield1010
This dataset contains 7690 10-second audio files in a standardised format, extracted from contributions on the Freesound archive which were labelled with the “field-recording” tag. Note that the original tagging (as well as the audio submission) is crowdsourced, so the dataset is not guaranteed to consist purely of “field recordings” as might be defined by practitioners. The intention is to represent the content of an archive collection on such a topic, rather than to represent a controlled definition of such a topic.
Dan Stowell
Centre for Digital Music (C4DM), Queen Mary University of London -
Freesound Loop Dataset
This dataset contains 9,455 loops from Freesound.org and the corresponding annotations. These loops have tempo, key, genre and instrumentation annotations made by MIR researchers.
More details can be found in “The Freesound Loop Dataset and Annotation Tool “ by António Ramires et al. (Paper)
António Ramires, Frederic Font, Dmitry Bogdanov, Jordan B. L. Smith, Yi-Hsuan Yang, Joann Ching, Bo-Yu Chen, Yueh-Kao Wu, Hsu Wei-Han, Xavier Serra
Music Technology Group (MTG), Universitat Pompeu Fabra, Tik Tok, Research Center for IT Innovation, Academia Sinica -
Freesound Loops 4k (FSL4)
This dataset contains ~4000 user-contributed loops uploaded to Freesound. Loops were selected by searching Freesound for sounds with the query terms
loopandbpm, and then automatically parsing the returned sound filenames, tags and textual descriptions to identify tempo annotations made by users. For example, a sound containing the tag120bpmis considered to have a ground truth of 120 BPM.
Frederic Font
Music Technology Group (MTG), Universitat Pompeu Fabra -
Freesound One-Shot Percussive Sounds
This dataset contains 10254 one-shot (single event) percussive sounds from Freesound and the corresponding timbral analysis. These were used to train the generative model for Neural Percussive Synthesis Parameterised by High-Level Timbral Features.
António Ramires, Pritish Chandna, Xavier Favory, Emilia Gómez, Xavier Serra
Music Technology Group (MTG), Universitat Pompeu Fabra -
FSD-FS
FSD-FS is a publicly-available database of human labelled sound events for few-shot learning. It spans across 143 classes obtained from the AudioSet Ontology and contains 43030 raw audio files collected from the FSD50K. FSD-FS is curated at the Centre for Digital Music, Queen Mary University of London.
Jinhua Liang, Huy Phan, Emmanouil Benetos
Centre for Digital Music, Queen Mary University of London -
FSD50K
FSD50K is an open dataset of human-labeled sound events containing 51,197 Freesound clips unequally distributed in 200 classes drawn from the AudioSet Ontology. Please check the Zenodo FSD50K page for more information about the dataset, download and citation information.
Eduardo Fonseca, Xavier Favory, Jordi Pons, Frederic Font, Xavier Serra, All the annotators!!!
Music Technology Group (MTG), Universitat Pompeu Fabra
-
FSDKaggle2018
FSDKaggle2018 is an audio dataset containing 11,073 audio files annotated with 41 labels of the AudioSet Ontology. FSDKaggle2018 has been used for the DCASE Challenge 2018 Task 2, which was run as a Kaggle competition titled Freesound General-Purpose Audio Tagging Challenge.
Eduardo Fonseca, Xavier Favory, Jordi Pons, Frederic Font, Manoj Plakal, Daniel P. W. Ellis, Xavier Serra
Music Technology Group (MTG), Universitat Pompeu Fabra, Google Research’s Machine Perception Team
-
FSDKaggle2019
FSDKaggle2019 is an audio dataset containing 29,266 audio files annotated with 80 labels of the AudioSet Ontology. FSDKaggle2019 has been used for the DCASE Challenge 2019 Task 2, which was run as a Kaggle competition titled Freesound Audio Tagging 2019. The dataset allows development and evaluation of machine listening methods in conditions of label noise, minimal supervision, and real-world acoustic mismatch. FSDKaggle2019 consists of two train sets and one test set. One train set and the test set consists of manually-labeled data from Freesound, while the other train set consists of noisily labeled web audio data from Flickr videos taken from the YFCC dataset.
Eduardo Fonseca, Manoj Plakal, Frederic Font, Daniel P. W. Ellis, Xavier Serra
Music Technology Group (MTG), Universitat Pompeu Fabra, Google Research’s Machine Perception Team
-
FSDnoisy18k
FSDnoisy18k is an audio dataset collected with the aim of fostering the investigation of label noise in sound event classification. It contains 42.5 hours of audio across 20 sound classes, including a small amount of manually-labeled data and a larger quantity of real-world noisy data.
Eduardo Fonseca, Mercedes Collado, Manoj Plakal, Daniel P. W. Ellis, Frederic Font, Xavier Favory, Xavier Serra
Music Technology Group (MTG), Universitat Pompeu Fabra, Google Research’s Machine Perception Team -
GISE-51
GISE-51 is an open dataset of 51 isolated sound events based on the FSD50K dataset. The release also includes the GISE-51-Mixtures subset, a dataset of 5-second soundscapes with up to three sound events synthesized from GISE-51. The GISE-51 release attempts to address some of the shortcomings of recent sound event datasets, providing an open, reproducible benchmark for future research and the freedom to adapt the included isolated sound events for domain-specific applications, which was not possible using existing large-scale weakly labelled datasets. GISE-51 release also included accompanying code for baseline experiments, which can be found at https://github.com/SarthakYadav/GISE-51-pytorch.
Sarthak Yadav, Mary Ellen Foster
University of Glasgow, UK -
Good-sounds dataset
This dataset contains monophonic recordings musical instruments playing two kinds of exercises: single notes and scales. The recordings were made in the Universitat Pompeu Fabra / Phonos recording studio by 15 different professional musicians, all of them holding a music degree and having some expertise in teaching, and uploaded to Freesound. 12 different instruments were recorded using one or up to 4 different microphones (depending on the recording session). For all the instruments the whole set of playable semitones in the instrument is recorded several times with different tonal characteristics. Each note is recorded into a separate mono .flac audio file of 48kHz and 32 bits. The tonal characteristics are explained both in the the following section and the related publication.
Oriol Romani Picas, Hector Parra Rodriguez, Dara Dabiri, Xavier Serra
Music Technology Group (MTG), Universitat Pompeu Fabra -
LAION-Audio-630K
LAION-Audio-630K is the largest audio-text dataset publicly available and a magnitude larger than previous audio-text datasets (by 2022-11-05). Notably, it combines eight distinct datasets, including 3000 hours of audio content from Freesound.
LAION Team, Yusong Wu, Ke Chen, Tianyu Zhang, Marianna Nezhurina, Yuchen Hui
LAION -
LibriFSD50K
LibriFSD50K is a dataset thatc ombines speech data form the LibriSpeech dataset and noise data from FSD50K. More information in the paper: https://arxiv.org/pdf/2105.04727.pdf
Efthymios Tzinis, Jonah Casebeer, Zhepei Wang, Paris Smaragdis
University of Illinois at Urbana-Champaign, Department of Computer Science, Urbana, IL, USA, Adobe Research, San Jose, CA, USA -
MAESTRO Synthetic - Multi-Annotator Estimated Strong Labels
MAESTRO synthetic contains 20 synthetic audio files created using Scaper, each of them 3 minutes long. The dataset was created for studying annotation procedures for strong labels using crowdsourcing. The audio files contain sounds from the following classes: car_horn, children_voices, dog_bark, engine_idling, siren, street_music. Audio files contain excerpts of recordings uploaded to Freesound. Please see FREESOUNDCREDITS.txt for an attribution list.
Audio files are generated using Scaper, with small changes to the synthesis procedure: Sounds were placed at random intervals, controlling for a maximum polyphony of 2. Intervals between two consecutive events are selected at random, but limited to 2-10 seconds. Event classes and event instances are chosen uniformly, and mixed with a signal-to-noise ratio (SNR) randomly selected between 0 and 20 dB over a Brownian noise background. Having two overlapping events from the same class is avoided.
Irene Martin Morato, Manu Harju, Annamaria Mesaros
Machine Listening Group, Tampere University -
SimSceneTVB Learning
This is a dataset of 600 simulated sound scenes of 45s each representing urban sound environments, simulated using the simScene Matlab library. The dataset is divided in two parts with a train subset (400 scenes) and a test subset (200 scenes) for the development of learning-based models. Each scene is composed of three main sources (traffic, human voices and birds) according to an original scenario, which is composed semi-randomly conditionally to five ambiances: park, quiet street, noisy street, very noisy street and square. Separate channels for the contribution of each source are available. The base audio files used for simulation are obtained from Freesound and LibriSpeech. The sound scenes are scaled according to a playback sound level in dB, which is drawn randomly but remains plausible according to the ambiance.
Felix Gontier, Mathieu Lagrange, Pierre Aumond, Catherine Lavandier, Jean-François Petiot
Ecole Centrale de Nantes, University of Paris Seine, University of Cergy-Pontoise, ENSEA -
SimSceneTVB Perception
This is a corpus of 100 sound scenes of 45s each representing urban sound environments, including: 6 scenes recorded in Paris; 19 scenes simulated using simScene to replicate recorded scenarios, including the 6 recordings in this corpus; 75 scenes simulated using simScene with diverse new scenarios, containing traffic, human voices and bird sources. The base audio files used for simulation are obtained from Freesound and LibriSpeech. The sound scenes are scaled according to a playback sound level in dB, which is drawn randomly but remains plausible according to the ambiance.
Felix Gontier, Mathieu Lagrange, Pierre Aumond, Catherine Lavandier, Jean-François Petiot
Ecole Centrale de Nantes, University of Paris Seine, University of Cergy-Pontoise, ENSEA -
Sound Events for Surveillance Applications
The Sound Events for Surveillance Applications (SESA) dataset files were obtained from Freesound. The dataset was divided between train (480 files) and test (105 files) folders. All audio files are WAV, Mono-Channel, 16 kHz, and 8-bit with up to 33 seconds. # Classes: 0 - Casual (not a threat) 1 - Gunshot 2 - Explosion 3 - Siren (also contains alarms).
Tito Spadini -
TUT Rare Sound Events 2017
TUT Rare Sound Events 2017 is a dataset used in the DCASE Challenge 2017 Task 2, focused on the detection of rare sound events in artificially created mixtures. It consists of isolated sound events for each target class and recordings of everyday acoustic scenes to serve as background. The target sound event categories are: Baby crying, Glass breaking, Gunshot. The background audio is part of TUT Acoustic Scenes 2016 dataset, and the isolated sound examples were collected from Freesound. Selection of sounds from Freesound was based on the exact label, selecting examples that had sampling frequency 44.1 kHz or higher.
Aleksandr Diment, Annamaria Mesaros, Toni Heittola
Tampere University of Technology -
Urban Sound 8K
This dataset contains 8732 labeled sound excerpts (<=4s) of urban sounds from 10 classes: air_conditioner, car_horn, children_playing, dog_bark, drilling, enginge_idling, gun_shot, jackhammer, siren, and street_music. The classes are drawn from the urban sound taxonomy. All excerpts are taken from field recordings uploaded to Freesound.
Justin Salamon, Christopher Jacoby, Juan Pablo Bello
Music and Audio Research Laboratory (MARL), New York University, Center for Urban Science and Progress (CUSP), New York University
-
USM-SED
USM-SED is a dataset for polyphonic sound event detection in urban sound monitoring use-cases. Based on isolated sounds taken from the FSD50k dataset, 20,000 polyphonic soundscapes are synthesized with sounds being randomly positioned in the stereo panorama using different loudness levels.
Jakob Abeßer
Semantic Music Technologies Group, Fraunhofer IDMT -
Vocal Imitation Set v1.1.3
The VocalImitationSet is a collection of crowd-sourced vocal imitations of a large set of diverse sounds collected from Freesound, which were curated based on Google’s AudioSet ontology. We expect that this dataset will help research communities obtain a better understanding of human’s vocal imitation and build a machine understand the imitations as humans do.
Bongjun Kim, Bryan Pardo
Dept. of Electrical Engineering and Computer Science, Northwestern University -
WavCaps
WavCaps, the first large-scale weakly-labelled audio captioning dataset, comprising approximately 400k audio clips with paired captions. We sourced audio clips and their raw descriptions from web sources and a sound event detection dataset (with 260k clips sourced from Freesound website). However, the online-harvested raw descriptions are highly noisy and unsuitable for direct use in tasks such as automated audio captioning. To overcome this issue, we propose a three-stage processing pipeline for filtering noisy data and generating high-quality captions, where ChatGPT, a large language model, is leveraged to filter and transform raw descriptions automatically.
Xinhao Mei, Chutong Meng, Haohe Liu, Qiuqiang Kong, Tom Ko, Chengqi Zhao, Mark D. Plumbley, Yuexian Zou, Wenwu Wang
Centre for Vision, Speech, and Signal Processing (CVSSP), University of Surrey, Johns Hopkins University, ByteDance, School of Electronic and Computer Engineering, Peking University