Freesound Datasets

Freesound Datasets is an online platform for the collaborative creation of open audio collections. It hosts several microtasks which enable people to contribute to the creation of datasets.
Openly available datasets are a key factor in the advancement of sound and music computing technologies. Quite a number of audio datasets are now available but often their creation process lack of transparency and they are not completly open and sharable. Moreover, they are often not large enough for supporting current machine learning needs. These shortcomings motivated our initiative in creating Freesound Datasets, an online platform for the collaborative creation of open audio collections. It leverages Freesound (>400k sounds) as a source of open audio content, relies on a community to sustainably crowdsource high-quality sound annotations, and it follows the principles of transparency, openness, dynamic character, and sustainability.
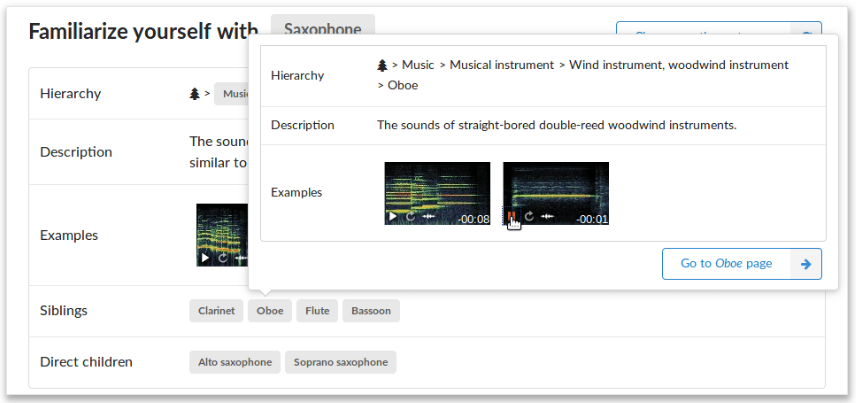
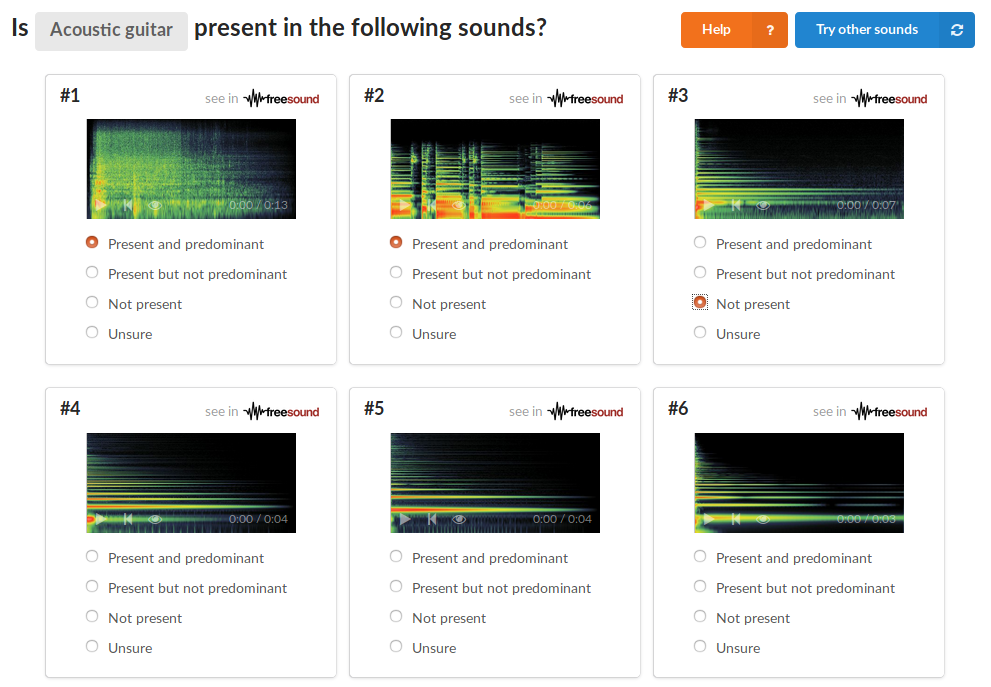
In particular, we started the creation of FSD, a dataset of everyday sounds, containing thousands of audio samples from Freesound and organised following the AudioSet Ontology. FSD presents annotations that express the presence of a sound category in audio samples. The creation of FSD started with the automatic population of each category in the AudioSet Ontology with a number of candidate audio samples from Freesound. This process automatically generated over 600k candidate annotations. To verify the validity of these automatically generated annotations, we developed a validation tool with an interface that helps users to understand a category and its context in the AudioSet Ontology.
More information can be found in our ISMIR2017 paper.
By: Xavier Favory, Eduardo Fonseca, Jordi Pons, Frederic Font
Released: 1 April 2018
URL: https://datasets.freesound.org
Code: https://github.com/MTG/freesound-datasets